
In online shopping applications, the daily insertion of new products requires an overwhelming annotation effort. Usually done by humans, it comes at a huge cost and yet generates high rates of noisy/missing labels that seriously hinder the effectiveness of CNNs in multi-label classification. We propose SELF-ML, a classification framework that exploits the relation between visual attributes and appearance together with the “low-rank” nature of the feature space. It learns a sparse reconstruction of image features as a convex combination of very few images - a basis - that are correctly annotated. Building on this representation, SELF-ML has a module that relabels noisy annotations from the derived combination of the clean data. Due to such structured reconstruction, SELF-ML gives an explanation of its label-flipping decisions. Experiments on a real-world shopping dataset show that SELF-ML significantly increases the number of correct labels even with few clean annotations.
“Explainable Noisy Label Flipping for Multi-Label Fashion Image Classification”
Abstract Paper - Workshop Computer Vision for Fashion, Art and Design, CVPR 2021
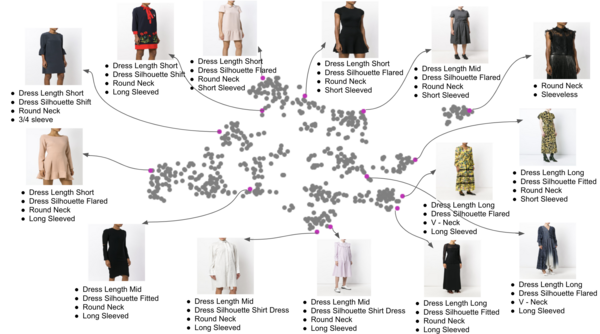
Image classification is a classical and fundamental Computer Vision problem. Among the possible settings, multi-label image classification appears among the most challenging ones as a single image can be associated with large dozens or even hundreds of concepts.
Multi-label arises more frequently than the single-label (multi-class) setting as real-world images are naturally associated with multiple labels describing, for instance, objects or attributes. Although less frequent in the literature, obtaining rich visual descriptions through multi-label classification is a more challenging supervised learning task. This is due to the diverse and complex image contents that, on the one hand, require intense annotation effort and, on the other hand, produce entangled feature representations.
When considering large-scale visual datasets this simply becomes intractable to be performed by humans and, even when attempted, it usually originates incorrect and inconsistent annotations. This is why devising mechanisms to perform this task in an automatic manner becomes of paramount importance.
Multi-label datasets are specifically affected by label noise, which can be either close to random or be systematic. CNNs based classification methods are able to deal relatively well with small amounts of the first type of noise due to their high dimensionality and generalization ability, yet their performance is severely affected by the second as they “memorize” wrongly given labels, especially if they are consistently wrong. We find both types of errors in fashion datasets, predominantly for multi-label classification tasks. Despite this fact, and perhaps due to its higher complexity, there are much fewer works in the literature addressing classification with noisy labels on multi-label settings than on multi-class.
Contributions
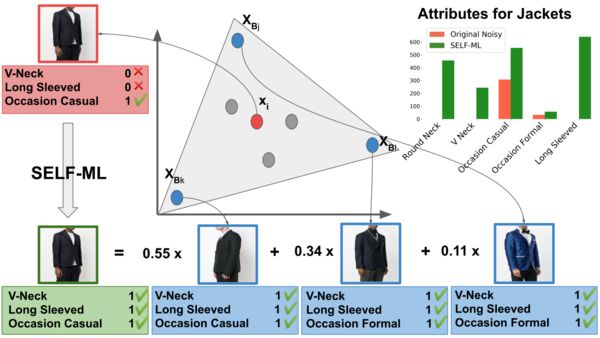
In this paper we tackle the noisy labels issue by introducing Self Explainable Noisy Label Flipping for Multi-Label (SELF-ML) for image classification, a deep learning framework that is able to correct noisy labels from very few annotated training examples. SELF-ML is based on the assumptions that visually similar images have similar visual attributes and that the feature space learned by CNNs is low-rank to learn a sparse reconstruction of image features (with noisy annotations) as a convex combination of a very limited number of images (which form a basis) that are correctly annotated. Using the previous sparse representation, a noisy label flipping module is able to correct the noisy training labels from the clean set of labels. Experiments on a fashion dataset show that SELF-ML substantially increases the number of correct labels even with very few clean annotations as supervision and outperforms popular approaches using the same clean labels. Contrary to previous label correcting methods, SELF-ML is also able to provide an explanation for all its label flipping decisions.
Our contributions are three-fold:
-
We propose the SELF-ML framework that integrates 4 modules: feature extraction, classifier, self-explainable reconstruction, and noisy label flipping. The explainable reconstruction module learns to reconstruct image features, previously learned by the feature extractor and classifier, from a sparse “basis”. If the attributes of the images of this basis are “cleaned”, the noisy label flipping module learns to correct the noisy labels during model training, leading to remarkable classification gains. SELF-ML is also much less prone to overfitting than fine-tuning.
-
By training SELF-ML to obtain a reconstruction of the input image features based on the set of basis images, our flipping mechanism will be interpretable and explainable.
-
We show SELF-ML effectiveness on a multi-label fashion dataset with label imbalance and noise.